La relajante construcción de una enorme cinta de Möbius en madera
microsiervos.comKyle Toth se dedica a mostrar cómo fabrica objetos en madera. Algo que tiene su encanto e intríngulis, y que va desde mesas a cajones e incluso tablas para cortar pizzas. Siete días se pasó grabó el proceso de construcción de una enorme cinta de Möbius en madera.


QWant, y los motores de búsqueda Europeos, alternativas a Google
redeszone.netA lo que está consiguiendo DuckDuckGo es a lo que aspiran sitios como Mojeek de Gran Bretaña, Qwant de Francia, Unbubble en Alemania o la suiza Swisscows. Todos tienen algo en común, no rastrean los datos de los usuarios, ni filtran los resultados ni muestran anuncios según “comportamiento”. Estos sitios están creciendo en medio de la implementación de las nuevas regulaciones de privacidad europeas (GDPR) y los numerosos escándalos de tráfico de datos y violación de derechos que han despertado la conciencia pública sobre las montañas de inform
España en mapas (para descargar en pdf)
twitter.comUna síntesis geográfica" que resume en más de 800 mapas y más de 600 páginas el Atlas Nacional . Compendio de la geografía y la historia de España a través de mapas, gráficos, tablas, textos e imágenes, interrelacionados y con el objetivo de transmitir lo fundamental del medio natural y humano del país. La publicación, elaborada por el Instituto Geográfico Nacional, pertenece a la serie Compendios del Atlas Nacional de España.
"Expedición a Marte"
youtube.comEste programa da vida a una de las grandes sagas de la Era Espacial: la épica tarea de conseguir que los robots Spirit y Opportunity llegasen a Marte y los fascinantes viajes de exploración que emprendieron. La historia cobra vida gracias a imágenes hasta ahora inéditas sacadas de los archivos del Laboratorio de Propulsión a Chorro (JPL), testimonios personales de científicos e ingenieros que participaron en la misión y animaciones realistas de los robots sobre el terreno marciano. Documental 2018/1080/90 min. | Relacionadas en #1

Mitología: lista de divinidades y dioses celtíberos
redhistoria.comLos celtíberos fueron una serie de pueblos prerromanos celtas, o celtizados, que habitaron la zona de la península ibérica denominada Celtiberia desde la Edad del Bronce (siglo XII a.C.) hasta la romanización de Hispania, desde los siglos II al I a.C.
Los empresarios quieren más inmigrantes, los obreros y parados no
Este artículo lo redacto para recoger en él todos los comentarios de un forero del diario.es, cuyo nick es: fb_683995204Que la izquierda sea inmigracionista es el suicidio de la izquierda, los obreros no quieren mas inmigrantes porque la saturacion del mercado laboral con mano de obra solo favorece y enriquece a los empresarios, como la izquierda no defienda a su clase obrera, sea antiinmigracionista, proteccionista y nacionalista va a desaparecer.....El CAPITAL usa la inmigracion masiva para PRECARIZAR el mercado laboral, pagar salarios ridiculos a los obreros y aumentar sus beneficios, y si los obreros protestan les llaman racisas y xenofobos . Lo lamentable es que los partidos "socialistas", (¿obreros?) han caido en la trampa, han abandonado a los obreros, por eso han perdido tambien su voto.Esto lo explica muy bien Verstrynge: https://www.youtube.com/watch?v=i-9M53FmjOIhttps://youtu.be/ThnzCIoPjmghttps://www.youtube.com/watch?v=5gBO2MeUuYACon 900.000 parados Andalucia tiene:-500.000 inmigrantes extracomunitarios, entre ellos 200.000 africanos, 200.000 sudamericanos , 48.500 de europa del este no comunitarios y 41.000 asiáticos-73.000 rumanosAlmería: 86.000 parados, tasa de paro 25% .100.000 inmigrantes de fuera de la Union Europea39.183 marroquies28.717 rumanos7.201 ecuatorianos4.343 senegaleses3.804 lituanos3.595 bulgaros3.372 rusos3.372 colombianos2.651 maliensesSolo los empresarios quieren mas inmigrantes, los obreros NO.https://www.lasexta.com/programas/al-rojo-vivo/entrevistas/el-rotundo-analisis-de-jorge-verstrynge-sobre-la-derrota-de-la-izquierda-en-andalucia-se-cosecha-lo-que-se-siembra-video_201812035c0540e60cf21af43017d85e.html?fbclid=IwAR18gtUvVDpbyL_M72WK4S5V5Vp4xyNJ-FO7MUPkixYKyxhH2AcH1kq08nIEl paro y contratos irregulares a inmigrantes tiran a la baja los jornales de vendimia en Tierra de Barros http://www.eldiario.es/eldiarioex/blog/Extremadura-Tierra_de_Barros-convenio-ciudadanos-irregulares_6_302079819.html Unos vecinos mios, padre e hijo, curraban talando almendros por 9€ la hora. Sin embargo ahora estan parados por que inmigrantes realizan el mismo trabajo por 3€ la hora....el empresario encantado... Cientos de jornaleros del campo murciano se rebelan contra la explotación laboral en sus empresas http://www.lacronicadelpajarito.es/region/cientos-jornaleros-del-campo-murciano-se-rebelan-contra-explotacion-laboral-sus-empresas#comment-3062La izquierda debe empezar a proteger a su clase obrera, a ser antiinmigración y proteccionista o se hundirá del todo.En la misma línea que el partido de izquierda alemán De Pie. http://menea.me/1sdwyy en la línea que Anguita y Monereo veían venir esta debacle de la izquierda: http://menea.me/1skf3el presidente del partido comunista húngaro, explica como están en contra de la inmigración masiva, y porque los partidos de izquierda europeos han perdido los votos de la clase trabajadora: https://www.youtube.com/watch?v=vIo5iF1YsWY
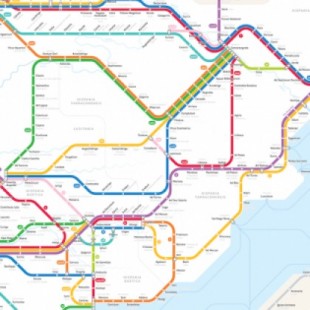
Calzadas romanas de la Península Ibérica en forma de red de metro
sashat.meElegí seguir el Itinerario de Antonino estrictamente, lo que significaba que tenía que lidiar con muchas líneas paralelas. Esto me obligó a un nuevo diseño, pero creo que al final se ve bien. "Número de línea" generalmente corresponde al número en el Itinerario de Antonino. Los siguientes números de línea no coinciden con el Itinerario de Antonine. La razón de esto es que un par de rutas de Antonino eran ambiguas y no se colocaban fácilmente en un mapa, mientras que faltaban algunas rutas importantes para las cuales hay evidencia arqueológica.
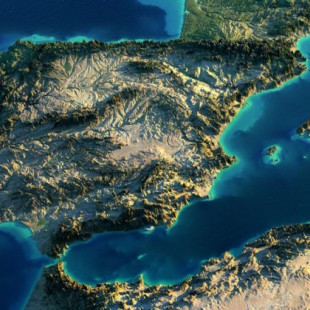
La influencia de la geografía en la historia de España
geografiainfinita.comImagina el océano Atlántico, el Mediterráneo y los Pirineos. Los límites de la península dan al mundo ibérico un carácter excéntrico y relativamente aislado en relación con el continente al que pertenece. La península, por un lado se abre ampliamente, gracias a una enorme periferia costera expuesta a las influencias externas, pero por otro lado ofrece resistencia a quien quiere adentrarse en su territorio, mediante sierras, grandes mesetas y un clima riguroso.
Visite Timor Oriental - Un anuncio honesto del Gobierno de Australia [ENG]
youtube.comDescubra en este anuncio satírico acerca de la nación paradisíaca de Timor Oriental y sobre cómo el gobierno amigo de Australia saquea sus recursos naturales y los condena a la miseria mientras enriquece a sus amiguetes y juzga en tribunales secretos a quien lo denuncia en nombre de la seguridad nacional.
El truco ganador del Campeonato Mundial de Magia te dejará seis minutos con la boca abierta
es.gizmodo.comPedirte que veas un vídeo de Youtube de seis minutos es mucho pedir cuando Internet ofrece otros entretenimientos que requieren solo unos segundos de tu atención. Pero el mago Eric Chien se las arregla para incluir tantos trucos imposibles en la rutina ganadora del Campeonato Mundial de Magia que en realidad desearías que durase más.
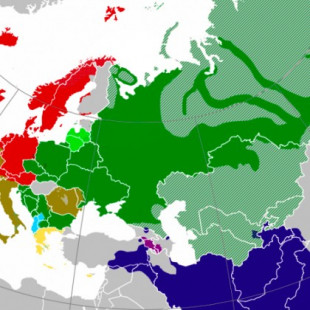
La expansión y el origen de las lenguas indoeuropeas
geografiainfinita.comEn el siglo XVIII, el francés Gaston-Laurent Coeurdoux viajó hasta la India como misionero. Allí propuso, por primera vez, la relación entre el sánscrito, el latín y el griego, y más adelante, incluso, con el alemán y el ruso.Pero fue el trabajo del inglés William Jones, uno de los más grandes filólogos de la época contemporánea, el que daría inicio a las teorías indoeuropeas.
¿Podría un pasajero aterrizar un avión?
youtube.comEl tema de hoy es una de las preguntas que mas frecuentemente se hacen, "Podría un pasajero aterrizar un avión?" Mi amiga Carolina, no tiene mas conexión con el mundo de la aviación, mas allá de volar de vez en cuando, en vacaciones, obviamente como pasajera. Tan pronto como tomó asiento, la parte mas difícil fue establecer comunicación entre ella y yo, que oficiaba como ATC, Control de Tráfico Aéreo... [Subtítulos disponibles en español]

La Voyager 2 está a punto de dejar atrás el Sistema Solar para adentrarse en el espacio interestelar
xataka.comLas sondas Voyager son una de las cosas que más debería fascinarnos y enorgullecernos como humanidad. Hemos conseguido enviar una pizca de humanidad a miles de millones de kilómetros de la Tierra, con la esperanza de que en algún momento alguien encuentre esos mensajes en forma de sonda y sepa que hay alguien más en el universo, nosotros. Ahora, la Voyager 2 está a punto de conseguir otro hito en su historia: entrar en el espacio interestelar.
Multiplicación de los panes y los plásticos
youtube.comAdvertencia, este vídeo no es para personas sensibles. Un pescador nos muestra lo que se encuentra en el intestino de sus capturas en el día a día de su trabajo en la mar.
La sorprendente vida de Hans Zimmer
youtube.comHans Zimmer es el compositor de Piratas del Caribe, Interstellar, Origen, la trilogía de Batman, y hasta de El Rey León. Pero su carrera empezó por unos derroteros tan distintos, que analizar su trayectoria es fascinante. En esta entrevista hablamos con Hans Zimmer de cómo ha compuesto la banda sonora de algunas de sus películas más conocidas, y hacemos un repaso a toda su carrera.
¿Cómo se ensambló la Estación Espacial Internacional?
youtube.com¿Qué hacen los astronautas en la estación espacial? ¿Qué países trabajan en ella? ¿La ha visitado algún turista? ¿Hasta cuándo operará? ¿Por dónde salen a hacer las caminatas espaciales? Veamos esta gran estructura detallada... mente.
Jugoslavija 1972
youtube.comUna película sin texto que muestra la vida cotidiana en la Yugoslavia de los años setenta.

Manipulando texto en el terminal
atareao.esEsto de manipular texto en el terminal te puede sonar extraño, o crees que raramente lo vas a utilizar… nada mas lejos de la realidad,una de las operaciones mas habituales que haces en el terminal es cambiar el nombre o la extensión a un archivo,pero, ¿qué pasa cuando tienes que renombrar de forma masiva 10 archivos? ¿y si en lugar de ser 10 son 100 ó 1.000?…. ¿Si tienes 1.000 imágenes en formato JPEG y las quieres convertir a PNG?. En este artículo te mostraré algunas de las posibilidades que te ofrece bash para manipular texto.

Cosas raras de los húngaros
mamaexpatriada.comTodo expatriado experimenta un profundo sentimiento de extrañeza respecto a la cultura y costumbres del país al que emigró. Según los expertos dicho sentimiento se conoce como: “cultural shock” y se estima que desaparece por sí solo a los 6 meses o el primer año de la estancia en el nuevo país. Hace muy poco me di cuenta de que a pesar de llevar más de 4 años viviendo en Hungría, tener 50% de sangre húngara en mis venas (mi familia paterna es de aquí), hablar el idioma y estar casada con un húngaro, sigo en “shock” respecto a muchas costumbres.

Así cuelan los cosmonautas rusos alcohol en el espacio
es.rbth.com"Todas las personas que vuelan le dirán que un sorbo de coñac en el espacio alivia la tensión y tiene un efecto positivo en el organismo" dice el dos veces héroe de la Unión Soviética Valeri Ryimin; sin embargo llevar alcohol al espacio está oficialmente prohibido... Motivo por el cual los cosmonautas rusos se las han ingeniado de múltiples maneras para llevarlo en diferentes escondites e incluso para aprovechar hasta la última gota en gravedad cero. La opinión común es que el coñac armenio es la mejor bebida alcohólica para el espacio.
Este es el increíble vehículo vintage soviético de 8 ruedas encontrado en Siberia
es.rbth.comUn usuario de la red social VKontakte ha descubierto un vehículo anfibio todoterreno de ocho ruedas, creado en los años 50 por la oficina de diseño de la planta de tractores hidráulicos de Cheliábinsk, informan medios rusos.


Podcasts de divulgación científica
Como adicto a los podcasts he hecho una lista de mis favoritos en divulgación científica. Veo que es un tema recurrente en los comentarios de muchos envíos y no está mal tener un repositorio con todos los enlaces.He recopilado todos los que tengo de esta temática en ivoox, seguramente haya más en otras plataformas. Os invito a colaborar con más enlaces en los comentarios.La Mecánica del CaracolDe Radio Euskadi.Divulgación científica general y para todo público. Con contenidos didácticos orientados a público más infantil, entrevistas y columnas.Astronomía y algo másAstronomía y temas relacionados, con algunos programas un poco "meta" donde se habla sobre divulgación.Principio de IncertidumbreDe Extremadura Radio.Divulgación científica general. Monográficos de entrevistas en profundidad con investigadores.Coffee Break, Señal y RuidoDivulgación científica general pero muy enfocada a astrofísica, cosmología, astronomía y otros temas relacionados. En formato tertulia, donde todos los panelistas son científicos.Radio SkylabEnfocado a astronáutica, exploración espacial, astronomía y temas relacionados. Aunque a veces tocan otros temas de divulgación científica.Ciencia FrescaDe cienciaes.comActualidad científica general.La BuhardillaActualidad científica general en clave de humor.Los 3 ChanchitosActualidad científica general.Catástrofe UltravioletaDivulgación científica general. Monográficos que incluyen entrevistas.Pa Ciència la Nostra (QEPD)Actualidad científica general en clave de humor en catalán. Publicaron su último programa en junio de 2017.Universo ParaleloMonográficos de divulgación científica general.El Abrazo del OsoMonográficos de divulgación científica, cultura e historia.
Os invito a colaborar con más enlaces en los comentarios.La Mecánica del CaracolDe Radio Euskadi.Divulgación científica general y para todo público. Con contenidos didácticos orientados a público más infantil, entrevistas y columnas.Astronomía y algo másAstronomía y temas relacionados, con algunos programas un poco "meta" donde se habla sobre divulgación.Principio de IncertidumbreDe Extremadura Radio.Divulgación científica general. Monográficos de entrevistas en profundidad con investigadores.Coffee Break, Señal y RuidoDivulgación científica general pero muy enfocada a astrofísica, cosmología, astronomía y otros temas relacionados. En formato tertulia, donde todos los panelistas son científicos.Radio SkylabEnfocado a astronáutica, exploración espacial, astronomía y temas relacionados. Aunque a veces tocan otros temas de divulgación científica.Ciencia FrescaDe cienciaes.comActualidad científica general.La BuhardillaActualidad científica general en clave de humor.Los 3 ChanchitosActualidad científica general.Catástrofe UltravioletaDivulgación científica general. Monográficos que incluyen entrevistas.Pa Ciència la Nostra (QEPD)Actualidad científica general en clave de humor en catalán. Publicaron su último programa en junio de 2017.Universo ParaleloMonográficos de divulgación científica general.El Abrazo del OsoMonográficos de divulgación científica, cultura e historia.
El nacimiento de una casa de madera
youtube.comSe trata de una película documental que descubre el proceso de construcción de una casa de madera con herramientas de mano, de materiales locales, a partir de bosques hasta el espacio a habitar. Construí mi casa con los árboles que derribé con un hacha y dos hombres con sierra, en mi bosque. Lo hice siguiendo la investigación del calendario del viejo carpintero de que los árboles de coníferas deberían ser talados en los primeros días de enero cuando la luna nueva se eleve y los árboles caducifolios deberían ser derribados en el invierno...
Lo efímero del hipervínculo I: Introducción y principales archivos web actuales

 En próximos artículos se analizarán: 2) Lo efímero del hipervínculo II: Memento Time Travel y más archivos web actuales" class="content-link" style="color: rgb(227, 86, 20)" data-toggle="popover" data-popover-type="link" data-popover-url="/tooltip/link/efimero-hipervinculo-ii-memento-time-travel-mas-archivos-web">Lo efímero del hipervínculo II: Memento Time Travel y más archivos web actuales, 3) los archivos web pasados y futuros, 4) los de de tipo "favoritos, las "pasarelas", programas y extensiones, 5) iniciativas públicas y empresariales, 6) la automatización del archivado, 7) beneficios y 8) problemas.
En próximos artículos se analizarán: 2) Lo efímero del hipervínculo II: Memento Time Travel y más archivos web actuales" class="content-link" style="color: rgb(227, 86, 20)" data-toggle="popover" data-popover-type="link" data-popover-url="/tooltip/link/efimero-hipervinculo-ii-memento-time-travel-mas-archivos-web">Lo efímero del hipervínculo II: Memento Time Travel y más archivos web actuales, 3) los archivos web pasados y futuros, 4) los de de tipo "favoritos, las "pasarelas", programas y extensiones, 5) iniciativas públicas y empresariales, 6) la automatización del archivado, 7) beneficios y 8) problemas. La rotura de enlaces o descomposición de enlaces es el proceso por el cual los hipervínculos conducen a páginas que no se encuentran disponibles de manera temporal o permanente.Esta situación puede suceder de muchas maneras. Desde un fallo en el servidor, una página que se traslada sin la adecuada redirección, contenido dinámico o no visible a terceros (por uso de burbujas de filtrado basadas en geolocalización o personalización o por requerir registro con contraseña), por la expiración del dominio o del certificado de seguridad, por bloqueo gubernamental, por ataque DDOS, por desaparición de una empresa, apagón, porque ese día una página web proteste y no deje acceso a su contenido a los usuarios, etc.
La rotura de enlaces o descomposición de enlaces es el proceso por el cual los hipervínculos conducen a páginas que no se encuentran disponibles de manera temporal o permanente.Esta situación puede suceder de muchas maneras. Desde un fallo en el servidor, una página que se traslada sin la adecuada redirección, contenido dinámico o no visible a terceros (por uso de burbujas de filtrado basadas en geolocalización o personalización o por requerir registro con contraseña), por la expiración del dominio o del certificado de seguridad, por bloqueo gubernamental, por ataque DDOS, por desaparición de una empresa, apagón, porque ese día una página web proteste y no deje acceso a su contenido a los usuarios, etc.
 La memoria de Internet es corta y frágil tal y como se ha demostrado en varios estudios [1] [2] [3] con cifras escalofriantes. Que un enlace no esté localizable en unos años no sólo es molesto para un navegante cualquiera sino que provoca pérdida de información en ámbitos laborales, jurídicos y académicos.En un estudio [2] se afirma: "tomando como referencia 160.000 URL (direcciones web) de repositorios científicos, el estudio más grande hasta ese momento, dio como resultado que un sorprendente 45% (66.096) de las URL referenciadas desde arXiv todavía existen pero no han sido preservadas para futuras generaciones y un 28% de los recursos referenciados por artículos de la University of North Texas (UNT) se han perdido".Es lo que se denomina poéticamente en inglés como "link rot" ("descomposición de enlaces"). Además, el contenido de un enlace, aunque este esté disponible, puede haber variado tanto que ya no sirva como referencia ("content drift" o "deriva de contenido", lo que conduce al "reference rot" o "descomposición de referencias"), lo que a veces es difícil de detectar.Por eso se han puesto en marcha varios proyectos de archivado (vídeo) de Internet y/o de datos/documentos; algunos realizados para salvar la historia de Internet en general y otros enfocados hacia el ámbito académico.Hay tres diferentes tipos de archivado: desde el cliente ("client-side"), transaccional ("transaction-based") y desde el servidor ("server-side"). Los dos últimos requieren de la colaboración del propietario del servidor, por lo que no son tan importantes (al menos para nosotros) [4].Los proyectos de archivado de páginas web más relevantes en general son en los que el usuario final puede realizar el proceso por sí mismo. [...] Aunque prometedores, los programas de escritorio o extensiones que realizan la misma tarea no son muy conocidos.Los más conocidos son los que disponen de formularios para archivar el contenido mediante una URL proporcionada por el usuario ("client-side"). Sin embargo, el número de iniciativas estatales (generalmente archivos o bibliotecas nacionales), públicas y privadas es abrumadora, pero con escasa repercusión en la gran mayoría debido a que su acceso y consulta no están promocionados y su ampliación no depende del usuario.Por el contrario, otros proyectos, aunque sean de mucho menor tamaño (Archive.is fue desarrollado por una sola persona) tienen una gran importancia para el usuario final. En la actualidad se están desarrollando aplicaciones de escritorio que pueden facilitar la tarea, pero con cada vez menos usuarios en el escritorio no parece que eso contribuya a un mayor uso. Existen extensiones que se agregan al navegador o "botones de acciones de favoritos" (bookmarklets) [A].Hay proyectos de archivado web que también desaparecen (incluso de instituciones), lo que nos indica la necesidad de una alta calidad en los que usemos. Han aparecido como setas decenas de servicios similares que no reúnen las características para ser denominados "archivadores web". Seguramente muchos de estos servicios, asociados a gestores de favoritos, quebrarán o desaparecerán en un futuro cercano, además su enfoque no es de tipo público.El orden en el que aparecen los sitios de archivo puede parecer aleatorio pero sigue mi criterio personal (un balance entre importancia, confiabilidad y facilidad de uso) que se ha ido formando a lo largo de años de los años. Se mencionan estos archivos:1ª parte: Wayback Machine, Webrecorder.io, Perma.cc, Archive.is.2ª parte: Memento, WebCite, Freezepage.com, Megalodon.jp, Archive.st.Memento es un visor para muchos de ellos.
La memoria de Internet es corta y frágil tal y como se ha demostrado en varios estudios [1] [2] [3] con cifras escalofriantes. Que un enlace no esté localizable en unos años no sólo es molesto para un navegante cualquiera sino que provoca pérdida de información en ámbitos laborales, jurídicos y académicos.En un estudio [2] se afirma: "tomando como referencia 160.000 URL (direcciones web) de repositorios científicos, el estudio más grande hasta ese momento, dio como resultado que un sorprendente 45% (66.096) de las URL referenciadas desde arXiv todavía existen pero no han sido preservadas para futuras generaciones y un 28% de los recursos referenciados por artículos de la University of North Texas (UNT) se han perdido".Es lo que se denomina poéticamente en inglés como "link rot" ("descomposición de enlaces"). Además, el contenido de un enlace, aunque este esté disponible, puede haber variado tanto que ya no sirva como referencia ("content drift" o "deriva de contenido", lo que conduce al "reference rot" o "descomposición de referencias"), lo que a veces es difícil de detectar.Por eso se han puesto en marcha varios proyectos de archivado (vídeo) de Internet y/o de datos/documentos; algunos realizados para salvar la historia de Internet en general y otros enfocados hacia el ámbito académico.Hay tres diferentes tipos de archivado: desde el cliente ("client-side"), transaccional ("transaction-based") y desde el servidor ("server-side"). Los dos últimos requieren de la colaboración del propietario del servidor, por lo que no son tan importantes (al menos para nosotros) [4].Los proyectos de archivado de páginas web más relevantes en general son en los que el usuario final puede realizar el proceso por sí mismo. [...] Aunque prometedores, los programas de escritorio o extensiones que realizan la misma tarea no son muy conocidos.Los más conocidos son los que disponen de formularios para archivar el contenido mediante una URL proporcionada por el usuario ("client-side"). Sin embargo, el número de iniciativas estatales (generalmente archivos o bibliotecas nacionales), públicas y privadas es abrumadora, pero con escasa repercusión en la gran mayoría debido a que su acceso y consulta no están promocionados y su ampliación no depende del usuario.Por el contrario, otros proyectos, aunque sean de mucho menor tamaño (Archive.is fue desarrollado por una sola persona) tienen una gran importancia para el usuario final. En la actualidad se están desarrollando aplicaciones de escritorio que pueden facilitar la tarea, pero con cada vez menos usuarios en el escritorio no parece que eso contribuya a un mayor uso. Existen extensiones que se agregan al navegador o "botones de acciones de favoritos" (bookmarklets) [A].Hay proyectos de archivado web que también desaparecen (incluso de instituciones), lo que nos indica la necesidad de una alta calidad en los que usemos. Han aparecido como setas decenas de servicios similares que no reúnen las características para ser denominados "archivadores web". Seguramente muchos de estos servicios, asociados a gestores de favoritos, quebrarán o desaparecerán en un futuro cercano, además su enfoque no es de tipo público.El orden en el que aparecen los sitios de archivo puede parecer aleatorio pero sigue mi criterio personal (un balance entre importancia, confiabilidad y facilidad de uso) que se ha ido formando a lo largo de años de los años. Se mencionan estos archivos:1ª parte: Wayback Machine, Webrecorder.io, Perma.cc, Archive.is.2ª parte: Memento, WebCite, Freezepage.com, Megalodon.jp, Archive.st.Memento es un visor para muchos de ellos. 1 - Páginas web que archivan públicamente (presente)
1 - Páginas web que archivan públicamente (presente)
 Nombre: Wayback Machine (WM) (web.archive.org) supone el esfuerzo más grande para preservar las páginas web a lo largo de la historia de Internet y la WWW. Es el epítome de la "arqueología de Internet".Fecha de lanzamiento: 1996. Acceso público: 2001. Posibilidad de guardar páginas: Otoño de 2012.Descripción: Fue fundada por Brewster Kahle (que además fundó Alexa), con el propósito de salvar una "Internet en llamas" y convertir el IA en una "Biblioteca de Alejandría 2.0". Aparte de la propia sección de Internet Archive que cuenta con la posibilidad de subir música/archivos propios para su difusión y muchas otras características (secciones para documentar fechas concretas, canales de televisión, videojuegos, etc.), la página propiamente dicha de WM tiene dos enfoques primordiales: "web crawls" (esto es, rastreo masivo de "páginas conocidas") y posibilidad de adquirir páginas específicas por parte del usuario (lo que se conoce como "live crawl", "archivado bajo demanda"). En un principio hacían uso de los rastreos de Alexa, pero después empezaron ellos mismos a hacer los rastreos.Wayback Machine de Internet Archive es el epítome de la "arqueología de Internet".Cuentas: No es necesario crearse una (aunque con ella puedes llevar un registro de las páginas que has guardado). Dicha cuenta permite disfrutar de los otros servicios en Internet Archive ya mencionados y que ahora no nos interesan.Velocidad de guardado / facilidad de uso: La velocidad es algo lenta, aunque adquirir de manera directa las imágenes es más rápido que en otros archivadores. La navegación es sencilla una vez conocidas ciertas particularidades. El esquema URL es así: web.archive.org/web/[FECHA]/[URI] (los signos "[]" marcan lugares donde se sustituye en la URL), por lo que es sencillo cambiar de URL o de fecha en la propia barra de direcciones. Veremos que es muy sencillo comprobar si una página está archivada o guardarla desde la propia barra de direcciones. Usando asteriscos podemos acceder a un directorio con todas las versiones de una misma URL: web.archive.org/web/*/[URI], (https://web.archive.org/web/*/http://jakeukalane.deviantart.com" target="_blank" class="content-link external" style="color: rgb(227, 86, 20)">ejemplo) o incluso a todas las direcciones archivadas de un mismo directorio: web.archive.org/web/*/[URI]/*, (https://jakeukalane.deviantart.com/*" target="_blank" class="content-link external" style="color: rgb(227, 86, 20)">ejemplo). No había búsqueda por palabras y el filtrado una vez establecida una URL demandaba cantidades enormes de RAM. Afortunadamente, ha sido incorporada una búsqueda por palabras clave y el filtrado es más veloz.Limitaciones / desventajas / problemas: No tiene limitaciones de IP, pero cuando se archivan una cantidad importante de enlaces seguidos (+100) las cookies pueden provocar un bucle de redireccionamiento. Una vez borradas se puede continuar con el archivado. No presenta una captura de imagen de cómo se ha cargado el sitio. Las guías disponibles por parte de WM son algo escuetas en cuanto a ejemplos, siendo mucho más detallada la versión de la Wikipedia.En archivos antiguos que en el momento de la adquisición se veían bien pueden dejar de hacerlo si la página cambia el esquema de las URL de las imágenes (pese a que la dirección antigua redireccione a la actual). En mi opinión esto ha pasado porque WM no archiva todo el contenido de manera explícita sino que deja "enlaces/accesos directos" a lo que espera encontrar en la web (e intenta encontrar archivos capturados en otro momento). Al cambiar las URL de la versión en línea, las imágenes dejan de estar disponibles. Es debido a no se recogen todos los recursos que se intenta archivar. Esto no ocurre en todos los casos o si se guardan las direcciones de las imágenes explícitamente. A veces es necesario añadir un :80 para poder ver la página web, aunque la mayoría de las veces sí se muestra http://web.archive.org/web/20120526123736/http://batjorge.deviantart.com/art/vintage-structures-299453066" target="_blank" class="content-link external" style="color: rgb(227, 86, 20)">bien sin ello.Otro de los problemas de WM es la divergencia temporal de algunos recursos, dando lugar a incoherencias temporales.Para archivar vídeos de YouTube el proceso es algo tedioso, aunque se puede llegar a conseguir (he visto alguno archivado, aunque yo no lo haya conseguido).Al ser un servicio mixto (mitad usuario, mitad robot), obedecía el criterio de exclusión de robots o archivo robots.txt, incluso cuando el archivado se producía a petición de un único usuario. Algunos archivos robots.txt son introducido por empresas que han comprado dominios que han expirado, lo que hacía que fuera inaccesible el contenido de miles y miles de páginas web a las que su dueño original no había introducido ningún criterio de exclusión. Internet Archive respondió a este problema diciendo que estudiarían eliminar el criterio de robots.txt. Google, por ejemplo, no recomienda usar el robots.txt para evitar que su rastreador web indexe un sitio y hay muchos rastreadores que no hacen caso a este criterio. Durante un tiempo, con mandar un correo e incluir el archivo robots.txt era suficiente para excluir el sitio. Sin embargo, ahora piden más datos (para evitar que terceros bloqueen contenidos del archivo).
Nombre: Wayback Machine (WM) (web.archive.org) supone el esfuerzo más grande para preservar las páginas web a lo largo de la historia de Internet y la WWW. Es el epítome de la "arqueología de Internet".Fecha de lanzamiento: 1996. Acceso público: 2001. Posibilidad de guardar páginas: Otoño de 2012.Descripción: Fue fundada por Brewster Kahle (que además fundó Alexa), con el propósito de salvar una "Internet en llamas" y convertir el IA en una "Biblioteca de Alejandría 2.0". Aparte de la propia sección de Internet Archive que cuenta con la posibilidad de subir música/archivos propios para su difusión y muchas otras características (secciones para documentar fechas concretas, canales de televisión, videojuegos, etc.), la página propiamente dicha de WM tiene dos enfoques primordiales: "web crawls" (esto es, rastreo masivo de "páginas conocidas") y posibilidad de adquirir páginas específicas por parte del usuario (lo que se conoce como "live crawl", "archivado bajo demanda"). En un principio hacían uso de los rastreos de Alexa, pero después empezaron ellos mismos a hacer los rastreos.Wayback Machine de Internet Archive es el epítome de la "arqueología de Internet".Cuentas: No es necesario crearse una (aunque con ella puedes llevar un registro de las páginas que has guardado). Dicha cuenta permite disfrutar de los otros servicios en Internet Archive ya mencionados y que ahora no nos interesan.Velocidad de guardado / facilidad de uso: La velocidad es algo lenta, aunque adquirir de manera directa las imágenes es más rápido que en otros archivadores. La navegación es sencilla una vez conocidas ciertas particularidades. El esquema URL es así: web.archive.org/web/[FECHA]/[URI] (los signos "[]" marcan lugares donde se sustituye en la URL), por lo que es sencillo cambiar de URL o de fecha en la propia barra de direcciones. Veremos que es muy sencillo comprobar si una página está archivada o guardarla desde la propia barra de direcciones. Usando asteriscos podemos acceder a un directorio con todas las versiones de una misma URL: web.archive.org/web/*/[URI], (https://web.archive.org/web/*/http://jakeukalane.deviantart.com" target="_blank" class="content-link external" style="color: rgb(227, 86, 20)">ejemplo) o incluso a todas las direcciones archivadas de un mismo directorio: web.archive.org/web/*/[URI]/*, (https://jakeukalane.deviantart.com/*" target="_blank" class="content-link external" style="color: rgb(227, 86, 20)">ejemplo). No había búsqueda por palabras y el filtrado una vez establecida una URL demandaba cantidades enormes de RAM. Afortunadamente, ha sido incorporada una búsqueda por palabras clave y el filtrado es más veloz.Limitaciones / desventajas / problemas: No tiene limitaciones de IP, pero cuando se archivan una cantidad importante de enlaces seguidos (+100) las cookies pueden provocar un bucle de redireccionamiento. Una vez borradas se puede continuar con el archivado. No presenta una captura de imagen de cómo se ha cargado el sitio. Las guías disponibles por parte de WM son algo escuetas en cuanto a ejemplos, siendo mucho más detallada la versión de la Wikipedia.En archivos antiguos que en el momento de la adquisición se veían bien pueden dejar de hacerlo si la página cambia el esquema de las URL de las imágenes (pese a que la dirección antigua redireccione a la actual). En mi opinión esto ha pasado porque WM no archiva todo el contenido de manera explícita sino que deja "enlaces/accesos directos" a lo que espera encontrar en la web (e intenta encontrar archivos capturados en otro momento). Al cambiar las URL de la versión en línea, las imágenes dejan de estar disponibles. Es debido a no se recogen todos los recursos que se intenta archivar. Esto no ocurre en todos los casos o si se guardan las direcciones de las imágenes explícitamente. A veces es necesario añadir un :80 para poder ver la página web, aunque la mayoría de las veces sí se muestra http://web.archive.org/web/20120526123736/http://batjorge.deviantart.com/art/vintage-structures-299453066" target="_blank" class="content-link external" style="color: rgb(227, 86, 20)">bien sin ello.Otro de los problemas de WM es la divergencia temporal de algunos recursos, dando lugar a incoherencias temporales.Para archivar vídeos de YouTube el proceso es algo tedioso, aunque se puede llegar a conseguir (he visto alguno archivado, aunque yo no lo haya conseguido).Al ser un servicio mixto (mitad usuario, mitad robot), obedecía el criterio de exclusión de robots o archivo robots.txt, incluso cuando el archivado se producía a petición de un único usuario. Algunos archivos robots.txt son introducido por empresas que han comprado dominios que han expirado, lo que hacía que fuera inaccesible el contenido de miles y miles de páginas web a las que su dueño original no había introducido ningún criterio de exclusión. Internet Archive respondió a este problema diciendo que estudiarían eliminar el criterio de robots.txt. Google, por ejemplo, no recomienda usar el robots.txt para evitar que su rastreador web indexe un sitio y hay muchos rastreadores que no hacen caso a este criterio. Durante un tiempo, con mandar un correo e incluir el archivo robots.txt era suficiente para excluir el sitio. Sin embargo, ahora piden más datos (para evitar que terceros bloqueen contenidos del archivo).
 Los dueños de páginas web (una vez demostrado que realmente lo son) pueden pedir que se elimine el contenido definitivamente de archive.org. Eso es perjudicial para la memoria de Internet (el resultado final es que páginas archivadas en un inicio quedan inaccesibles, algo que no pasa en otros como WebCite, al sólo buscar ese archivo en el momento de archivar la página), pero que WM admita estas peticiones la dota de un refuerzo legal. Otro motivo válido es cuando se tiene un servidor funcionando con un ancho de banda limitado. Obviamente hay personas que están en contra de que se haya abandonado el bloqueo mediante robots.txt aduciendo que hordas de webmasters cabreados iban a bloquear por IP a Internet Archive, lo que sería muy contraproducente. Habrá alguno, pero no es tan grave la cuestión como la quieren hacer parecer y tampoco conseguirán ser excluidos de todos los archivos digitales. Además, esas personas asumen como cierto que el archivo robots.txt es algún tipo de estándar con validez legal cuando esto es falso.Otros problemas, como alojamiento de malware, phising, doxxing, copyright "vulnerado", etc., son consustanciales a la mayoría de archivos y se tratarán en el futuro.Ventajas: Implementa el protocolo Memento. Debido a su enfoque global, es capaz de almacenar PDF (ejemplo), exe/archivos comprimidos (mspaint.zip), o vídeo: ejemplo: falsa alarma de llegada de misiles a Hawai / contexto), incluso de gran tamaño (en mis pruebas hasta 200 MiB, más allá puede dar errores 504 "gateway time out"). En general el esquema de la URL de añomesdíahoraminutossegundos (por ejemplo: 20190309131331), es imitado por otros sitios de archivado. Dispone de bookmarklets ("botones de acciones de favoritos") [A] y extensiones. Con el esquema "web.archive.org/web/[URI]" se puede comprobar si un sitio ya está archivado (si lo está, muestra la última versión archivada, si no está y no presenta ningún problema, te da la opción de archivar la página) y con el esquema "web.archive.org/save/[URI]" se puede archivar de manera directa. Puede ser rearchivado fácilmente. Tiene botones de compartir en redes sociales (Facebook y Twitter).Confiabilidad: Es el archivo web por excelencia y si en algún momento falla de manera permanente (por falta de financiación u otro motivo, p.ej. censura) tendremos un grave problema. Ha tenido períodos de caída (como cualquier otro sitio web), debido a fallos de infraestructura, apagones, mantenimiento de la plataforma, que han durado horas. Hay archivos que https://plus.google.com/+LinuxMagazineEdici%C3%B3nenCastellano/posts/GWMuJhcUkrU" target="_blank" class="content-link external" style="color: rgb(227, 86, 20)">han dejado de estar disponibles debido, a fallos de hardware. Hay países que han bloqueado a WM como la India.Otros datos: Es el archivo más grande y otros archivos e instituciones. Como la CDL que ha traspasado el núcleo de su archivo al servicio de pago de WM, Archive-it, abandonado su propia solución. En un interesante artículo, Ed Summers advertía en 2015 sobre que haya mayor cooperación y más propuestas de archivado (para evitar un SPOF o "punto único de fallo").Wayback Machine es el archivo web por excelencia y tendremos un grave problema si en algún momento falla de manera permanente.WM es el archivo web más antiguo con archivado bajo demanda que continua en línea hasta hoy. Internet Archive es miembro fundador de la IIPC (International Internet Preservation Consortium) junto con otras 11 instituciones: Biblioteca Nazionale Centrale di Firenze, Real Biblioteca de Dinamarca, Biblioteca Nacional de Francia, de Finlandia, de Suecia, de Islandia, de Noruega, de Australia, Library and Archives de Canada, The British Library y The Library of Congress. La Biblioteca Nacional de España se incorporó en 2010.Sus desarrolladores produjeron Heritrix, un rastreador muy conocido. Su formato, WARC, es un estándar ISO y es muy usado entre las iniciativas de archivado web de las grandes bibliotecas. Entorno a sus herramientas y formatos se ha desarrollado todo un grupo de herramientas que en ArchiveTeam llaman "ecosistema WARC". Volveré en un artículo futuro sobre estas herramientas.
Los dueños de páginas web (una vez demostrado que realmente lo son) pueden pedir que se elimine el contenido definitivamente de archive.org. Eso es perjudicial para la memoria de Internet (el resultado final es que páginas archivadas en un inicio quedan inaccesibles, algo que no pasa en otros como WebCite, al sólo buscar ese archivo en el momento de archivar la página), pero que WM admita estas peticiones la dota de un refuerzo legal. Otro motivo válido es cuando se tiene un servidor funcionando con un ancho de banda limitado. Obviamente hay personas que están en contra de que se haya abandonado el bloqueo mediante robots.txt aduciendo que hordas de webmasters cabreados iban a bloquear por IP a Internet Archive, lo que sería muy contraproducente. Habrá alguno, pero no es tan grave la cuestión como la quieren hacer parecer y tampoco conseguirán ser excluidos de todos los archivos digitales. Además, esas personas asumen como cierto que el archivo robots.txt es algún tipo de estándar con validez legal cuando esto es falso.Otros problemas, como alojamiento de malware, phising, doxxing, copyright "vulnerado", etc., son consustanciales a la mayoría de archivos y se tratarán en el futuro.Ventajas: Implementa el protocolo Memento. Debido a su enfoque global, es capaz de almacenar PDF (ejemplo), exe/archivos comprimidos (mspaint.zip), o vídeo: ejemplo: falsa alarma de llegada de misiles a Hawai / contexto), incluso de gran tamaño (en mis pruebas hasta 200 MiB, más allá puede dar errores 504 "gateway time out"). En general el esquema de la URL de añomesdíahoraminutossegundos (por ejemplo: 20190309131331), es imitado por otros sitios de archivado. Dispone de bookmarklets ("botones de acciones de favoritos") [A] y extensiones. Con el esquema "web.archive.org/web/[URI]" se puede comprobar si un sitio ya está archivado (si lo está, muestra la última versión archivada, si no está y no presenta ningún problema, te da la opción de archivar la página) y con el esquema "web.archive.org/save/[URI]" se puede archivar de manera directa. Puede ser rearchivado fácilmente. Tiene botones de compartir en redes sociales (Facebook y Twitter).Confiabilidad: Es el archivo web por excelencia y si en algún momento falla de manera permanente (por falta de financiación u otro motivo, p.ej. censura) tendremos un grave problema. Ha tenido períodos de caída (como cualquier otro sitio web), debido a fallos de infraestructura, apagones, mantenimiento de la plataforma, que han durado horas. Hay archivos que https://plus.google.com/+LinuxMagazineEdici%C3%B3nenCastellano/posts/GWMuJhcUkrU" target="_blank" class="content-link external" style="color: rgb(227, 86, 20)">han dejado de estar disponibles debido, a fallos de hardware. Hay países que han bloqueado a WM como la India.Otros datos: Es el archivo más grande y otros archivos e instituciones. Como la CDL que ha traspasado el núcleo de su archivo al servicio de pago de WM, Archive-it, abandonado su propia solución. En un interesante artículo, Ed Summers advertía en 2015 sobre que haya mayor cooperación y más propuestas de archivado (para evitar un SPOF o "punto único de fallo").Wayback Machine es el archivo web por excelencia y tendremos un grave problema si en algún momento falla de manera permanente.WM es el archivo web más antiguo con archivado bajo demanda que continua en línea hasta hoy. Internet Archive es miembro fundador de la IIPC (International Internet Preservation Consortium) junto con otras 11 instituciones: Biblioteca Nazionale Centrale di Firenze, Real Biblioteca de Dinamarca, Biblioteca Nacional de Francia, de Finlandia, de Suecia, de Islandia, de Noruega, de Australia, Library and Archives de Canada, The British Library y The Library of Congress. La Biblioteca Nacional de España se incorporó en 2010.Sus desarrolladores produjeron Heritrix, un rastreador muy conocido. Su formato, WARC, es un estándar ISO y es muy usado entre las iniciativas de archivado web de las grandes bibliotecas. Entorno a sus herramientas y formatos se ha desarrollado todo un grupo de herramientas que en ArchiveTeam llaman "ecosistema WARC". Volveré en un artículo futuro sobre estas herramientas.

 Nombre: Webrecorder.io (WR) (webrecorder.io/) constituye una versión modernizada del propósito de Internet Archive Wayback Machine. Está enfocado explícitamente en adquirir contenido multimedia, generado en redes sociales o contenido que no se puede archivar sin la interacción del usuario.Fecha de lanzamiento: Agosto 2016.Descripción / cuentas: Surgió como un proyecto de Rhizome. Se enfoca exclusivamente en archivar contenido a petición del usuario. Es necesario crearse una cuenta (que proporciona 5 GiB) lo que otorga mayor privacidad al usuario que guarda las páginas. Los archivos se pueden hacer públicos (ejemplo) o dejar como privados (y exportarlos en formato WARC) y también se pueden eliminar. Permite adquirir páginas que no es posible guardarlas correctamente en ningún otro, como por ejemplo artstation, instagram (ejemplo) (sí, muchos ejemplos son de cosas mías) o páginas que tengan "complicados" sistemas anti-archivo (sí, Motherboard, es inevitable, todo se puede archivar —volveré en el futuro varias veces sobre este punto—) o con desplazamiento interminable . El archivado sigue un flujo "natural", cuando está en "modo grabación" cada acción realizada genera un registro en la web, por lo que desplegables, JavaScript, vídeos, etc., son capaces de funcionar en la versión "capturada". Las diferentes direcciones web visitadas se guardan en una sesión que puede ser visualizada a modo de lista.Webrecorder.io es el modelo a seguir dentro de los archivadores web del futuro: descentralizados, personales, con respeto a la privacidad del usuario y "portables".Velocidad de guardado / facilidad de uso: Archiva más rápido que Wayback Machine (presupongo que esto es debido a que guarda a la vez que carga el contenido para tener una mejor respuesta. WM primero guarda todos los componentes y luego carga la página adquirida). La búsqueda de webs ya archivadas es más engorrosa al ser archivos generados por particulares donde las direcciones cambian debido a los diferentes nombres de usuario y de sesión. Ejemplo: webrecorder.io/[nombre-de-usuario]/[nombre-de-sesión]/FECHA/[URI]. Los apartados en cursiva no es fácil conocerlos.Quizás por ello no dispone de búsqueda integrada. Esto es probable que cambie en el futuro.Limitaciones /desventajas / problemas: No tiene extensiones para usar con el navegador. Supongo que para automatizar el proceso (ver Automatización en un futuro artículo) se puede usar la versión de escritorio Webrecorder Player. Además, si queremos recuperar un enlace privado tendremos que ir a nuestra cuenta.Ventajas: Implementa el protocolo Memento. Ignora el archivo robots.txt. Dispone de URL para archivado: webrecorder.io/record/ (aunque requiere estar ya logueado). Tiene "botón de acción de favoritos" [A].Webrecorder.io es el modelo a seguir dentro de los archivadores web: descentralizados, personales, innovadores y privados. También portables, al poderse exportar en formato WARC. Al tener el usuario el control, es más difícil tener una visión general de un archivo, pero este también puede ser más resistente a ataques legales futuros. Al fin y al cabo, un archivo web personal y privado en casi nada se diferencia de guardar una página en un ordenador particular, más que en la capacidad técnica de que el resultado sea preciso y sea reproducible por terceros en línea.Permite obtener archivos desde WM o desde cualquier archivo público (con la opción "patch this URL" —"parchea esta URL" obtener una "foto de pantalla" e incrustar en iframes. También tiene botones de compartir con redes sociales (twitter y facebook).Una cuestión muy importante y de la que no me había dado cuenta, es que no sólo permite exportar WARC sino también importarlos haciendo posible leer WARC de Internet Archive (una de las críticas de Ed Summers).Un nuevo añadido muy interesante es la nueva posibilidad (verano de 2018) de presentar las colecciones de manera pública y con una interfaz atractiva. Más recientemente aún (02-2019), ha sido mejorada y el resultado es espectacular demostrado por dos ejemplos: "https://webrecorder.io/despens/selling-dream-dance-" target="_blank" class="content-link external" style="color: rgb(227, 86, 20)">Selling Dream Dance" y "Forgotten Websites". Esto viene a hacer de WR la mezcla ideal entre un gestor de favoritos y un archivador, con la importante distinción con respecto a los gestores de favoritos en línea (aunque también hacen funciones de archivado) que el diseño interno está en función de la capacidad de archivar sitios y no al revés; el punto más importante: permite la exportación en archivos WARC.Además, las colecciones de este tipo (enfocadas a conservadores, "curators") son públicas, por lo que pueden ser archivadas a su vez en otros archivadores (aunque Archive.is y WM fallan en la tarea). PageDash, en cambio, sí puede archivarlo.Confiabilidad: Está patrocinado por Rhizome, que tiene varios proyectos similares y ha desarrollado herramientas del mismo estilo (como Colloq u Oldweb). También hicieron otros proyectos que hoy son curiosidades sobre visualización de nodos web. Están financiados por la https://en.wikipedia.org/wiki/Andrew_W._Mellon_Foundation." target="_blank" class="content-link external" style="color: rgb(227, 86, 20)">Andrew W. Mellon Foundation que también creo JSTOR, Archive Unleashed y ha financiado Memento.Otros datos: Dispone una opción de elegir el tipo de navegador para archivar o para ver el archivado, por lo que tecnologías que se queden obsoletas como flash o applets java serán emuladas para poder disfrutar de todo el contenido, aunque a veces no funciona. Debido a que provee una manera de descargar las sesiones en el citado formato WARC, hay quienes hacen volcados sus archivos a Wayback Machine.
Nombre: Webrecorder.io (WR) (webrecorder.io/) constituye una versión modernizada del propósito de Internet Archive Wayback Machine. Está enfocado explícitamente en adquirir contenido multimedia, generado en redes sociales o contenido que no se puede archivar sin la interacción del usuario.Fecha de lanzamiento: Agosto 2016.Descripción / cuentas: Surgió como un proyecto de Rhizome. Se enfoca exclusivamente en archivar contenido a petición del usuario. Es necesario crearse una cuenta (que proporciona 5 GiB) lo que otorga mayor privacidad al usuario que guarda las páginas. Los archivos se pueden hacer públicos (ejemplo) o dejar como privados (y exportarlos en formato WARC) y también se pueden eliminar. Permite adquirir páginas que no es posible guardarlas correctamente en ningún otro, como por ejemplo artstation, instagram (ejemplo) (sí, muchos ejemplos son de cosas mías) o páginas que tengan "complicados" sistemas anti-archivo (sí, Motherboard, es inevitable, todo se puede archivar —volveré en el futuro varias veces sobre este punto—) o con desplazamiento interminable . El archivado sigue un flujo "natural", cuando está en "modo grabación" cada acción realizada genera un registro en la web, por lo que desplegables, JavaScript, vídeos, etc., son capaces de funcionar en la versión "capturada". Las diferentes direcciones web visitadas se guardan en una sesión que puede ser visualizada a modo de lista.Webrecorder.io es el modelo a seguir dentro de los archivadores web del futuro: descentralizados, personales, con respeto a la privacidad del usuario y "portables".Velocidad de guardado / facilidad de uso: Archiva más rápido que Wayback Machine (presupongo que esto es debido a que guarda a la vez que carga el contenido para tener una mejor respuesta. WM primero guarda todos los componentes y luego carga la página adquirida). La búsqueda de webs ya archivadas es más engorrosa al ser archivos generados por particulares donde las direcciones cambian debido a los diferentes nombres de usuario y de sesión. Ejemplo: webrecorder.io/[nombre-de-usuario]/[nombre-de-sesión]/FECHA/[URI]. Los apartados en cursiva no es fácil conocerlos.Quizás por ello no dispone de búsqueda integrada. Esto es probable que cambie en el futuro.Limitaciones /desventajas / problemas: No tiene extensiones para usar con el navegador. Supongo que para automatizar el proceso (ver Automatización en un futuro artículo) se puede usar la versión de escritorio Webrecorder Player. Además, si queremos recuperar un enlace privado tendremos que ir a nuestra cuenta.Ventajas: Implementa el protocolo Memento. Ignora el archivo robots.txt. Dispone de URL para archivado: webrecorder.io/record/ (aunque requiere estar ya logueado). Tiene "botón de acción de favoritos" [A].Webrecorder.io es el modelo a seguir dentro de los archivadores web: descentralizados, personales, innovadores y privados. También portables, al poderse exportar en formato WARC. Al tener el usuario el control, es más difícil tener una visión general de un archivo, pero este también puede ser más resistente a ataques legales futuros. Al fin y al cabo, un archivo web personal y privado en casi nada se diferencia de guardar una página en un ordenador particular, más que en la capacidad técnica de que el resultado sea preciso y sea reproducible por terceros en línea.Permite obtener archivos desde WM o desde cualquier archivo público (con la opción "patch this URL" —"parchea esta URL" obtener una "foto de pantalla" e incrustar en iframes. También tiene botones de compartir con redes sociales (twitter y facebook).Una cuestión muy importante y de la que no me había dado cuenta, es que no sólo permite exportar WARC sino también importarlos haciendo posible leer WARC de Internet Archive (una de las críticas de Ed Summers).Un nuevo añadido muy interesante es la nueva posibilidad (verano de 2018) de presentar las colecciones de manera pública y con una interfaz atractiva. Más recientemente aún (02-2019), ha sido mejorada y el resultado es espectacular demostrado por dos ejemplos: "https://webrecorder.io/despens/selling-dream-dance-" target="_blank" class="content-link external" style="color: rgb(227, 86, 20)">Selling Dream Dance" y "Forgotten Websites". Esto viene a hacer de WR la mezcla ideal entre un gestor de favoritos y un archivador, con la importante distinción con respecto a los gestores de favoritos en línea (aunque también hacen funciones de archivado) que el diseño interno está en función de la capacidad de archivar sitios y no al revés; el punto más importante: permite la exportación en archivos WARC.Además, las colecciones de este tipo (enfocadas a conservadores, "curators") son públicas, por lo que pueden ser archivadas a su vez en otros archivadores (aunque Archive.is y WM fallan en la tarea). PageDash, en cambio, sí puede archivarlo.Confiabilidad: Está patrocinado por Rhizome, que tiene varios proyectos similares y ha desarrollado herramientas del mismo estilo (como Colloq u Oldweb). También hicieron otros proyectos que hoy son curiosidades sobre visualización de nodos web. Están financiados por la https://en.wikipedia.org/wiki/Andrew_W._Mellon_Foundation." target="_blank" class="content-link external" style="color: rgb(227, 86, 20)">Andrew W. Mellon Foundation que también creo JSTOR, Archive Unleashed y ha financiado Memento.Otros datos: Dispone una opción de elegir el tipo de navegador para archivar o para ver el archivado, por lo que tecnologías que se queden obsoletas como flash o applets java serán emuladas para poder disfrutar de todo el contenido, aunque a veces no funciona. Debido a que provee una manera de descargar las sesiones en el citado formato WARC, hay quienes hacen volcados sus archivos a Wayback Machine.

 Nombre: Perma.cc (perma.cc).Descripción: Es otro archivador web moderno fomentado por Harvard y otras grandes bibliotecas. Su enfoque es específicamente académico. También es muy usado en ámbitos legales. Está destinado a la preservación de larga duración (de verdad, no como otros ejemplos que veremos después).Fecha de lanzamiento: Septiembre 2013.Cuentas: Es necesario registrarse para efectuar un archivado de una página web. Se tiene acceso de manera gratuita a 10 archivados al mes.Velocidad de guardado / facilidad de uso: No soy capaz de valorar su velocidad de guardado porque lo he usado muy poco. Al hacer el artículo he descubierto que se pueden buscar URL guardadas mediante: perma-archives.org/warc/*/[URL] (https://perma-archives.org/warc/*/https://tuscriaturas.blogia.com" target="_blank" class="content-link external" style="color: rgb(227, 86, 20)">ejemplo).Similar a webrecorder.io en uso y filosofía (aunque con un enfoque académico), perma.cc parece el archivador web en el que confiar cuando queramos que algo jamás abandone la web, pero [...] apenas permite adquirir diez páginas al mes a las cuentas gratuitas.Limitaciones /desventajas / problemas: Haciendo este artículo he descubierto que es falso que no se pueda obtener una URL en formato largo. Sin embargo, no hay ninguna forma directa (desde perma.cc) de hallar dicho enlace. Las URL largas siguen este esquema: perma-archives.org/warc/[añomesdíahorasegundos]/[URI]. La manera más sencilla de optenerlas es a través de Memento, aunque se puede deducir la URL con el esquema dado: ejemplo URL corta / ejemplo de URL larga deducida. Las URL con este esquema no tienen la interfaz normal.No he encontrado los esquemas explicados en la documentación.Falla algo más que WR al archivar (normal, por otro lado). No puede guardar vídeos.Ventajas: Dispone de un botón de acción de favoritos [A] y de una extensión. Las páginas web archivadas se pueden marcar como públicas o privadas y se pueden descargar en formato WARC. Permite asociar varias páginas web a un solo archivo (o carpetas). La cuenta dispone de una clave API, supongo que para poder usarse en terceras aplicaciones.Ante un archivo robots.txt que bloquee su archivado anteriormente reaccionaba haciendo que la versión archivada no pudiera compartirse y se marcase de manera irrevocable como privada, actualmente sigue reaccionando así ante un robots.txt que tenga explícitamente excluido a la araña de perma.cc. Sin embargo, en el caso de ser un bloqueo genérico el archivo se hace automáticamente público.Confiabilidad: Dicen que han tomado medidas de duplicación, preservación y financiación a largo plazo, estando apoyados por grandes universidades y con un "detallado plan de contingencia". Similar a webrecorder.io en uso y filosofía, perma.cc parece el archivador web en el que confiar cuando queramos que algo jamás abandone la web, pero su modelo freemium apenas permite diez páginas archivadas al mes para los usuarios gratuitos, lo que, aunque permite una mayor sostenibilidad (hay dinero que entra y menos que sale) hace que sea menos conocido. Los archivados públicos son subidos automáticamente a Internet Archive.Otros datos: (Se pueden ver como ventajas o como desventajas): Una vez pasadas 24 horas los enlaces no se pueden eliminar. Se puede subir una foto de pantalla propia si las fotos de pantalla generadas no cargan. Al principio Perma.cc requería que un individuo asociado a una biblioteca, una revista o una corte penal "estableciera" ("vest") los enlaces para que pasaran a ser permanentes. Los archivados sin esta validación eran temporales y podían expirar si no se renovaban.
Nombre: Perma.cc (perma.cc).Descripción: Es otro archivador web moderno fomentado por Harvard y otras grandes bibliotecas. Su enfoque es específicamente académico. También es muy usado en ámbitos legales. Está destinado a la preservación de larga duración (de verdad, no como otros ejemplos que veremos después).Fecha de lanzamiento: Septiembre 2013.Cuentas: Es necesario registrarse para efectuar un archivado de una página web. Se tiene acceso de manera gratuita a 10 archivados al mes.Velocidad de guardado / facilidad de uso: No soy capaz de valorar su velocidad de guardado porque lo he usado muy poco. Al hacer el artículo he descubierto que se pueden buscar URL guardadas mediante: perma-archives.org/warc/*/[URL] (https://perma-archives.org/warc/*/https://tuscriaturas.blogia.com" target="_blank" class="content-link external" style="color: rgb(227, 86, 20)">ejemplo).Similar a webrecorder.io en uso y filosofía (aunque con un enfoque académico), perma.cc parece el archivador web en el que confiar cuando queramos que algo jamás abandone la web, pero [...] apenas permite adquirir diez páginas al mes a las cuentas gratuitas.Limitaciones /desventajas / problemas: Haciendo este artículo he descubierto que es falso que no se pueda obtener una URL en formato largo. Sin embargo, no hay ninguna forma directa (desde perma.cc) de hallar dicho enlace. Las URL largas siguen este esquema: perma-archives.org/warc/[añomesdíahorasegundos]/[URI]. La manera más sencilla de optenerlas es a través de Memento, aunque se puede deducir la URL con el esquema dado: ejemplo URL corta / ejemplo de URL larga deducida. Las URL con este esquema no tienen la interfaz normal.No he encontrado los esquemas explicados en la documentación.Falla algo más que WR al archivar (normal, por otro lado). No puede guardar vídeos.Ventajas: Dispone de un botón de acción de favoritos [A] y de una extensión. Las páginas web archivadas se pueden marcar como públicas o privadas y se pueden descargar en formato WARC. Permite asociar varias páginas web a un solo archivo (o carpetas). La cuenta dispone de una clave API, supongo que para poder usarse en terceras aplicaciones.Ante un archivo robots.txt que bloquee su archivado anteriormente reaccionaba haciendo que la versión archivada no pudiera compartirse y se marcase de manera irrevocable como privada, actualmente sigue reaccionando así ante un robots.txt que tenga explícitamente excluido a la araña de perma.cc. Sin embargo, en el caso de ser un bloqueo genérico el archivo se hace automáticamente público.Confiabilidad: Dicen que han tomado medidas de duplicación, preservación y financiación a largo plazo, estando apoyados por grandes universidades y con un "detallado plan de contingencia". Similar a webrecorder.io en uso y filosofía, perma.cc parece el archivador web en el que confiar cuando queramos que algo jamás abandone la web, pero su modelo freemium apenas permite diez páginas archivadas al mes para los usuarios gratuitos, lo que, aunque permite una mayor sostenibilidad (hay dinero que entra y menos que sale) hace que sea menos conocido. Los archivados públicos son subidos automáticamente a Internet Archive.Otros datos: (Se pueden ver como ventajas o como desventajas): Una vez pasadas 24 horas los enlaces no se pueden eliminar. Se puede subir una foto de pantalla propia si las fotos de pantalla generadas no cargan. Al principio Perma.cc requería que un individuo asociado a una biblioteca, una revista o una corte penal "estableciera" ("vest") los enlaces para que pasaran a ser permanentes. Los archivados sin esta validación eran temporales y podían expirar si no se renovaban.

 Nombre: Archive.is / archive.today. Archivador enfocado en permitir adquirir al usuario webs 2.0. Apareció antes que webrecorder.io. Busca almacenar el contenido de manera estática (eliminando Flash, vídeo, sonido, pdf, rss y xml y en general el contenido dinámico con JavaScript). Integra una captura de pantalla y una versión comprimida de todo el contenido.Fecha de lanzamiento: 2012.Descripción: Sistema alternativo a WM antes de que surgieran nuevas alternativas como WR o perma.cc y con mejoras substanciales con respecto a WebCite. El enfoque es diferente y fue el primero en permitir archivar páginas web que pedían explícitamente en su robots.txt que no fueran rastreadas. Sin embargo, esto parte de la concepción errónea de que Archive.is es un robot, cuando no lo es en absoluto, puesto que sólo se pueden archivar páginas a petición de un usuario. Esto parte de la concepción errónea de que el archivo robots.txt tiene algún tipo de validez legal, cuando ni siquiera es un estándar real (a pesar de que en muchos lugares se lo denomine incorrectamente como estándar).Cuentas: No existen cuentas de ningún tipo.Velocidad de guardado / facilidad de uso: El tiempo de guardado es bastante rápido en comparación con WM (Wayback Machine). Muy probablemente debido a eliminar ciertos elementos. En el caso de guardar imágenes explícitamente la velocidad es menor debido a que se tiene que generar un ZIP.Limitaciones /desventajas / problemas
Nombre: Archive.is / archive.today. Archivador enfocado en permitir adquirir al usuario webs 2.0. Apareció antes que webrecorder.io. Busca almacenar el contenido de manera estática (eliminando Flash, vídeo, sonido, pdf, rss y xml y en general el contenido dinámico con JavaScript). Integra una captura de pantalla y una versión comprimida de todo el contenido.Fecha de lanzamiento: 2012.Descripción: Sistema alternativo a WM antes de que surgieran nuevas alternativas como WR o perma.cc y con mejoras substanciales con respecto a WebCite. El enfoque es diferente y fue el primero en permitir archivar páginas web que pedían explícitamente en su robots.txt que no fueran rastreadas. Sin embargo, esto parte de la concepción errónea de que Archive.is es un robot, cuando no lo es en absoluto, puesto que sólo se pueden archivar páginas a petición de un usuario. Esto parte de la concepción errónea de que el archivo robots.txt tiene algún tipo de validez legal, cuando ni siquiera es un estándar real (a pesar de que en muchos lugares se lo denomine incorrectamente como estándar).Cuentas: No existen cuentas de ningún tipo.Velocidad de guardado / facilidad de uso: El tiempo de guardado es bastante rápido en comparación con WM (Wayback Machine). Muy probablemente debido a eliminar ciertos elementos. En el caso de guardar imágenes explícitamente la velocidad es menor debido a que se tiene que generar un ZIP.Limitaciones /desventajas / problemas
 A veces es complicado encontrar algunas páginas web ya archivadas, debido a que el buscador diferencia entre HTTP y HTTPS y entre "dominio.com" y "www.dominio.com" (eso en ocasiones es positivo también, al poder guardar una página web de varias formas).Hay algunas "pasarelas" (en un futuro artículo explicaré mi definición sobre lo que es una pasarela) que tampoco son detectadas por dicho buscador, haciendo que un archivo de una determinada página esté presente en dicha página pero no apareciendo en el listado completo. Esto es normal teniendo en cuenta la complejidad de las webs que pueden servir como pasarelas (aunque detecta cualquier redirección).Hay algunas páginas web que siguen un protocolo SSL estricto y que sólo pueden ser archivadas mediante el uso de "pasarelas" —que puede que no sigan ese protocolo de manera tan estricta—. Esto afecta a sitios web como Deviantart o Fandom (especialmente en las imágenes).Desde la versión adquirida no se puede averiguar la URL de los elementos originales. Las imágenes tienen URL alfanuméricas.Tiene un "tiempo de expiración" ("timeout") de 5 minutos que a veces no es suficiente para adquirir algunas páginas. También tiene un límite de 50 MB por página. Efectúa bloqueos temporales por IP (rechazo de conexión, nada drástico), que se pueden solventar mediante el reinicio del router. Sin embargo, hay que tenerlo en cuenta si se quieren adquirir muchas webs consecutivamente. Algunas páginas web como LinkedIn y otras con toneladas de contenido dinámico no se archivan bien con Archive.is . Hay ciertos dominios TLD (no recuerdo cuales pero eran compuestos o no muy comunes) que no se archivan bien (tengo la teoría de que Archive.is piensa que son extensiones de archivo). Las páginas web de Google como Drive o Presentaciones no se muestran bien.El esquema URL de archivo es "archive.is/?run=1&url=[URI]", muy compleja si la comparamos con la de WM.La URL que se genera por defecto es una versión acortada alfanumérica. El enlace largo y corto que se proveen en el menú de compartir por defecto no son en HTTPS. Quizás tenga que ver con que la versión HTTPS está bloqueada en Rusia.
A veces es complicado encontrar algunas páginas web ya archivadas, debido a que el buscador diferencia entre HTTP y HTTPS y entre "dominio.com" y "www.dominio.com" (eso en ocasiones es positivo también, al poder guardar una página web de varias formas).Hay algunas "pasarelas" (en un futuro artículo explicaré mi definición sobre lo que es una pasarela) que tampoco son detectadas por dicho buscador, haciendo que un archivo de una determinada página esté presente en dicha página pero no apareciendo en el listado completo. Esto es normal teniendo en cuenta la complejidad de las webs que pueden servir como pasarelas (aunque detecta cualquier redirección).Hay algunas páginas web que siguen un protocolo SSL estricto y que sólo pueden ser archivadas mediante el uso de "pasarelas" —que puede que no sigan ese protocolo de manera tan estricta—. Esto afecta a sitios web como Deviantart o Fandom (especialmente en las imágenes).Desde la versión adquirida no se puede averiguar la URL de los elementos originales. Las imágenes tienen URL alfanuméricas.Tiene un "tiempo de expiración" ("timeout") de 5 minutos que a veces no es suficiente para adquirir algunas páginas. También tiene un límite de 50 MB por página. Efectúa bloqueos temporales por IP (rechazo de conexión, nada drástico), que se pueden solventar mediante el reinicio del router. Sin embargo, hay que tenerlo en cuenta si se quieren adquirir muchas webs consecutivamente. Algunas páginas web como LinkedIn y otras con toneladas de contenido dinámico no se archivan bien con Archive.is . Hay ciertos dominios TLD (no recuerdo cuales pero eran compuestos o no muy comunes) que no se archivan bien (tengo la teoría de que Archive.is piensa que son extensiones de archivo). Las páginas web de Google como Drive o Presentaciones no se muestran bien.El esquema URL de archivo es "archive.is/?run=1&url=[URI]", muy compleja si la comparamos con la de WM.La URL que se genera por defecto es una versión acortada alfanumérica. El enlace largo y corto que se proveen en el menú de compartir por defecto no son en HTTPS. Quizás tenga que ver con que la versión HTTPS está bloqueada en Rusia.
 Ventajas: Implementa el protocolo Memento. No respeta el archivo robots.txt. Dispone de una interfaz en español (a la que he contribuido con algunas mejoras, así que no podía dejar de mencionarlo). Está en También tiene un menú para compartir los enlaces, con la versión larga de la URL, código markdown, código para enlazar a través de la imagen producida (en HTTPS) y un código wiki.Desde las imágenes capturadas se puede volver a la dirección alfanumérica de archivado. Una misma imagen archivada desde dos fuentes diferentes no se duplica en el archivo sino que se enlaza. Esto es importante en términos de sostenibilidad.Llega a archivar páginas que fallan estrepitosamente en otros archivadores (con excepción de webrecorder.io, pero también ocurre). Gasta menos memoria RAM que WM y es más segura.Es un archivador excepcional para adquirir cachés de diversos buscadores (incluso permite archivar la caché de Google cuando se le proporciona una dirección de un PDF, siempre y cuando Google la tenga ya, claro) o búsquedas en sí mismas (aunque el resultado de la búsqueda variará con el que se muestra en tú ordenador, seguramente dependiendo de la configuración de idioma del navegador sin interfaz gráfica que utiliza para archivar las páginas web o puede que se trate de una "violación de cookies", posibles en WM). Esto tiene su repercusión en que no es necesario un navegador para su uso.Las URL tienen este esquema año.día.mes-horaminutossegundos (ejemplo) pero también se pueden borrar los puntos y el guión para usar el mismo formato que en WM. Es decir "2019.02.20-202602" o "20190220202602". Eso hace que sea sencillo consultar versiones cercanas en el tiempo en ambos archivos.Se puede agregar un ancla a una determinada selección de texto en una página. Es decir, que de toda una página que puede ser muy grande, en la versión archivada se puede incluir explícitamente el lugar de la cita. Muy, muy útil (ejemplo). También se puede utilizar un porcentaje de la longitud de la página (ejemplo). Estas anclas funcionan con cualquiera de las versiones de Archive.is (acortadas o no, o con diferentes dominios).Aunque pensaba que Archive.is no era archivable por WM (y ese ha sido el caso siempre que lo he comprobado hasta el día de hoy), resulta que parece que se ha levantado dicha limitación y sí se puede conseguir —puede que tenga que ver con que archive.org ya no respeta el archivo robots.txt—, aunque hay que recurrir a ciertos trucos (como añadir id_ a la url para evitar una redirección —ver la guía de WM de Wikipedia—). También presenta algunos fallos con las imágenes (lo que es normal al ser un archivo de un archivo).Webrecorder.io puede archivar sin problema Archive.is y Archive.is puede archivar a WM (ejemplo).Utiliza ciertos webproxies para saltarse restricciones mediante IP como bigmama .El contenido es indexado en google (en ocasiones), lo que permite encontrar páginas webs caídas. El buscador acepta comandos complejos como uso de *, ? o "insite". Además cuenta con un buscador integrado de Google y de Yandex (que se activa cuando el de Google no encuentra nada), además del buscador de URL.
Ventajas: Implementa el protocolo Memento. No respeta el archivo robots.txt. Dispone de una interfaz en español (a la que he contribuido con algunas mejoras, así que no podía dejar de mencionarlo). Está en También tiene un menú para compartir los enlaces, con la versión larga de la URL, código markdown, código para enlazar a través de la imagen producida (en HTTPS) y un código wiki.Desde las imágenes capturadas se puede volver a la dirección alfanumérica de archivado. Una misma imagen archivada desde dos fuentes diferentes no se duplica en el archivo sino que se enlaza. Esto es importante en términos de sostenibilidad.Llega a archivar páginas que fallan estrepitosamente en otros archivadores (con excepción de webrecorder.io, pero también ocurre). Gasta menos memoria RAM que WM y es más segura.Es un archivador excepcional para adquirir cachés de diversos buscadores (incluso permite archivar la caché de Google cuando se le proporciona una dirección de un PDF, siempre y cuando Google la tenga ya, claro) o búsquedas en sí mismas (aunque el resultado de la búsqueda variará con el que se muestra en tú ordenador, seguramente dependiendo de la configuración de idioma del navegador sin interfaz gráfica que utiliza para archivar las páginas web o puede que se trate de una "violación de cookies", posibles en WM). Esto tiene su repercusión en que no es necesario un navegador para su uso.Las URL tienen este esquema año.día.mes-horaminutossegundos (ejemplo) pero también se pueden borrar los puntos y el guión para usar el mismo formato que en WM. Es decir "2019.02.20-202602" o "20190220202602". Eso hace que sea sencillo consultar versiones cercanas en el tiempo en ambos archivos.Se puede agregar un ancla a una determinada selección de texto en una página. Es decir, que de toda una página que puede ser muy grande, en la versión archivada se puede incluir explícitamente el lugar de la cita. Muy, muy útil (ejemplo). También se puede utilizar un porcentaje de la longitud de la página (ejemplo). Estas anclas funcionan con cualquiera de las versiones de Archive.is (acortadas o no, o con diferentes dominios).Aunque pensaba que Archive.is no era archivable por WM (y ese ha sido el caso siempre que lo he comprobado hasta el día de hoy), resulta que parece que se ha levantado dicha limitación y sí se puede conseguir —puede que tenga que ver con que archive.org ya no respeta el archivo robots.txt—, aunque hay que recurrir a ciertos trucos (como añadir id_ a la url para evitar una redirección —ver la guía de WM de Wikipedia—). También presenta algunos fallos con las imágenes (lo que es normal al ser un archivo de un archivo).Webrecorder.io puede archivar sin problema Archive.is y Archive.is puede archivar a WM (ejemplo).Utiliza ciertos webproxies para saltarse restricciones mediante IP como bigmama .El contenido es indexado en google (en ocasiones), lo que permite encontrar páginas webs caídas. El buscador acepta comandos complejos como uso de *, ? o "insite". Además cuenta con un buscador integrado de Google y de Yandex (que se activa cuando el de Google no encuentra nada), además del buscador de URL.
 Dispone de botón de acción de favoritos [A] y de extensiones. Dispone de una guía donde se explican muchos más datos (por ejemplo, para obtener archivos por año, por mes, el más antiguo o el más moderno. Soporta páginas web con caracteres especiales (ñ, kanjis). Hay un botón de reporte de abusos. Algunos usuarios se quejan de que no se retira contenido y otros de que sí se retira.Dispone de un blog de preguntas y respuestas donde atiende a las preguntas de los usuarios y corrige errores, dando una retroalimentación mayor que otros proyectos.Confiabilidad: En la Wikipedia inglesa ha habido discusiones muy acaloradas al respecto (debido a acusaciones sin pruebas por el uso de bots de edición). Es un sitio administrado privadamente por una única persona (y que emplea a otra) a diferencia de la mayoría de otros sitios web administrados por entes públicos.Contestando a esas dudas su responsable dijo: "Está financiado de manera privada. No hay finanzas complejas detrás. Puede parecer más o menos confiable comparándolo con una financiación de tipo "startup" o un proyecto de universidad, dependiendo de los riesgos que se tomen en cuenta. Mi muerte puede causar la interrupción del servicio, pero algo así como las nuevas condiciones del mercado o el cambio de jefe o un departamento, no". [...] "Todos los datos se almacenan en HDFS, el contenido textual se duplica 3 veces entre los servidores en diferentes centros de datos y las imágenes se duplican 2 veces. Todos los centros de datos están en Europa".Está financiado de manera privada. No hay complejas finanzas detrás. Puede parecer más o menos confiable comparándolo con una financiación de tipo "startup" o un proyecto de universidad, dependiendo de los riesgos que se tomen en cuenta.El sitio ha recibido ataques por parte de terceros, algunos bastante surrealistas y varios dominios han estado suspendidos. Incluso llegó a decir que al dominio .is le quedaba poca tiempo (aunque ha sido desmentido). Tiene otros dominios que funcionan exactamente igual: archive.today, archive.li, archive.fo, archive.vn, archive.md, archive.ph e incluso un onion, para tor: archivecaslytosk.onion. Esto puede verse como una inestabilidad, pero creo que la cuestión primordial es que si uno de esos dominios (que no el contenido) cae, hay opciones para acceder a través de otro dominio. El problema más importante serían los enlaces pero las versiones acortadas seguirían funcionando con el TLD correcto.Está censurado en Australia (en relación con los atentados de Christchurch, mismo motivo que El filtro de búsqueda por fecha de Youtube ha sido desactivado [EN]
Dispone de botón de acción de favoritos [A] y de extensiones. Dispone de una guía donde se explican muchos más datos (por ejemplo, para obtener archivos por año, por mes, el más antiguo o el más moderno. Soporta páginas web con caracteres especiales (ñ, kanjis). Hay un botón de reporte de abusos. Algunos usuarios se quejan de que no se retira contenido y otros de que sí se retira.Dispone de un blog de preguntas y respuestas donde atiende a las preguntas de los usuarios y corrige errores, dando una retroalimentación mayor que otros proyectos.Confiabilidad: En la Wikipedia inglesa ha habido discusiones muy acaloradas al respecto (debido a acusaciones sin pruebas por el uso de bots de edición). Es un sitio administrado privadamente por una única persona (y que emplea a otra) a diferencia de la mayoría de otros sitios web administrados por entes públicos.Contestando a esas dudas su responsable dijo: "Está financiado de manera privada. No hay finanzas complejas detrás. Puede parecer más o menos confiable comparándolo con una financiación de tipo "startup" o un proyecto de universidad, dependiendo de los riesgos que se tomen en cuenta. Mi muerte puede causar la interrupción del servicio, pero algo así como las nuevas condiciones del mercado o el cambio de jefe o un departamento, no". [...] "Todos los datos se almacenan en HDFS, el contenido textual se duplica 3 veces entre los servidores en diferentes centros de datos y las imágenes se duplican 2 veces. Todos los centros de datos están en Europa".Está financiado de manera privada. No hay complejas finanzas detrás. Puede parecer más o menos confiable comparándolo con una financiación de tipo "startup" o un proyecto de universidad, dependiendo de los riesgos que se tomen en cuenta.El sitio ha recibido ataques por parte de terceros, algunos bastante surrealistas y varios dominios han estado suspendidos. Incluso llegó a decir que al dominio .is le quedaba poca tiempo (aunque ha sido desmentido). Tiene otros dominios que funcionan exactamente igual: archive.today, archive.li, archive.fo, archive.vn, archive.md, archive.ph e incluso un onion, para tor: archivecaslytosk.onion. Esto puede verse como una inestabilidad, pero creo que la cuestión primordial es que si uno de esos dominios (que no el contenido) cae, hay opciones para acceder a través de otro dominio. El problema más importante serían los enlaces pero las versiones acortadas seguirían funcionando con el TLD correcto.Está censurado en Australia (en relación con los atentados de Christchurch, mismo motivo que El filtro de búsqueda por fecha de Youtube ha sido desactivado [EN]

 Nombre: WebCite® (webcitation.org) es una página de archivado pionera en el archivado de páginas web bajo demanda (desde algún tiempo después de 1997 hasta 2012 fue uno de los pocos archivos que permitían este tipo de archivado), con un enfoque académico y legal. Perteneció al IIPC (International Internet Preservation Consortium).Fecha de lanzamiento: 1997.Descripción: Al principio estuvo apoyado por la Universidad de Toronto. Incluyo este sitio de archivado web por motivos históricos (a pesar de que sigue en funcionamiento) porque su valor en la actualidad como método de archivado generalista es relativo. Y digo esto porque WebCite tiene un enfoque muy claro. Su propósito es preservar citas científicas, de ahí el amplio formulario antes de adquirir una página con su servicio. Otro apunte interesante es que fue el primer servicio que disponía de la posibilidad de que fuese el usuario el que adquiriese las páginas, antes que WM. No he conseguido averiguar el momento cuando se puso al público toda la plataforma, puesto que al principio estaba restringida a adquisición de referencias de artículos antes de ser publicados en revistas científicas.Archive Team: "Webcite es tan a prueba de balas que lo usamos en todas nuestras páginas [...]. Pero Archive Team no confía en ningún hombre o consorcio: afortunadamente WebCite provee el formulario conveniente donde solicitar hospedar un espejo".Cuentas: No es necesario tener una cuenta pero se necesita un correo para un archivado exitoso. Yo uso uno creado ex profeso.Velocidad de guardado / navegación: La velocidad de guardado depende de la cola de adquisiciones. Sin usar el botón de acción de favoritos [A] específico (que tiene que ser construido previamente), el formulario completo es enorme, aunque los datos obligatorios sólo son la URL y el correo electrónico. Solicita que se provea el lenguaje. La página está muy estructurada: inicio, preguntas frecuentes, noticias, solicitar (para unirse a la organización), miembros (las organizaciones que son miembros de WebCite), búsqueda, "comb" (para archivar varios enlaces de manera consecutiva), archivar y " botón de acción de favoritos".No dispone de una manera directa (escribir en la barra de direcciones) de buscar una página, hay que hacer esto a través del formulario correspondiente. Quizás sea para limitar el número de visitas y la carga del servidor.Limitaciones / desventajas / problemas: Yo tengo una opinión no muy positiva de este archivo. Esta opinión no es compartida por ArchiveTeam. La página contiene mucha información, quizás demasiada (sí, es gracioso que yo lo diga, aunque no deja de ser cierto), pero se echa de menos un menor número de formularios: varios se podrían combinar en la misma página, como en WM y en Archive.is donde búsqueda y archivado; en el caso de WebCite la de "comb" se podría incluir en una misma página.Los resultados de WebCite con algunas páginas web son bastante pobres.La desventaja más importante en mi opinión es que los resultados de algunas páginas web en WebCite son http://www.webcitation.org/query?url=https://www.meneame.net&date=2019-03-25 pobres en comparación con el resto de servicios mencionados anteriormente: Wayback Machine, Archive.is, meneame/20190326020342
o Perma.cc. Y servicios que he posicionado en mi clasificación personal como de menor importancia como Freezepage, Archive.st (con su 2019" class="content-link" style="color: rgb(227, 86, 20)" data-toggle="popover" data-popover-type="link" data-popover-url="/tooltip/link/2019">png completo) archivan la página más fielmente. Sólo fracasan en este caso Megalodon.jp y los servicios de caché (excepto sogou, que ignora la etiqueta meta no cache, aunque http://snapshot.sogoucdn.com/websnapshot?ie=utf8&url=http://www.meneame.net/&did=cd73728bc85adbca-6a7b5e4a9d9fbe2a-bcabb760432374ee937d35a2351a1341&k=254d189455e169b61777cbc13063c009&encodedquery=meneame&query=meneame&&p=40040100&dp=1&w=01020400&m=0&st=1, excepto usándose como http:
Nombre: WebCite® (webcitation.org) es una página de archivado pionera en el archivado de páginas web bajo demanda (desde algún tiempo después de 1997 hasta 2012 fue uno de los pocos archivos que permitían este tipo de archivado), con un enfoque académico y legal. Perteneció al IIPC (International Internet Preservation Consortium).Fecha de lanzamiento: 1997.Descripción: Al principio estuvo apoyado por la Universidad de Toronto. Incluyo este sitio de archivado web por motivos históricos (a pesar de que sigue en funcionamiento) porque su valor en la actualidad como método de archivado generalista es relativo. Y digo esto porque WebCite tiene un enfoque muy claro. Su propósito es preservar citas científicas, de ahí el amplio formulario antes de adquirir una página con su servicio. Otro apunte interesante es que fue el primer servicio que disponía de la posibilidad de que fuese el usuario el que adquiriese las páginas, antes que WM. No he conseguido averiguar el momento cuando se puso al público toda la plataforma, puesto que al principio estaba restringida a adquisición de referencias de artículos antes de ser publicados en revistas científicas.Archive Team: "Webcite es tan a prueba de balas que lo usamos en todas nuestras páginas [...]. Pero Archive Team no confía en ningún hombre o consorcio: afortunadamente WebCite provee el formulario conveniente donde solicitar hospedar un espejo".Cuentas: No es necesario tener una cuenta pero se necesita un correo para un archivado exitoso. Yo uso uno creado ex profeso.Velocidad de guardado / navegación: La velocidad de guardado depende de la cola de adquisiciones. Sin usar el botón de acción de favoritos [A] específico (que tiene que ser construido previamente), el formulario completo es enorme, aunque los datos obligatorios sólo son la URL y el correo electrónico. Solicita que se provea el lenguaje. La página está muy estructurada: inicio, preguntas frecuentes, noticias, solicitar (para unirse a la organización), miembros (las organizaciones que son miembros de WebCite), búsqueda, "comb" (para archivar varios enlaces de manera consecutiva), archivar y " botón de acción de favoritos".No dispone de una manera directa (escribir en la barra de direcciones) de buscar una página, hay que hacer esto a través del formulario correspondiente. Quizás sea para limitar el número de visitas y la carga del servidor.Limitaciones / desventajas / problemas: Yo tengo una opinión no muy positiva de este archivo. Esta opinión no es compartida por ArchiveTeam. La página contiene mucha información, quizás demasiada (sí, es gracioso que yo lo diga, aunque no deja de ser cierto), pero se echa de menos un menor número de formularios: varios se podrían combinar en la misma página, como en WM y en Archive.is donde búsqueda y archivado; en el caso de WebCite la de "comb" se podría incluir en una misma página.Los resultados de WebCite con algunas páginas web son bastante pobres.La desventaja más importante en mi opinión es que los resultados de algunas páginas web en WebCite son http://www.webcitation.org/query?url=https://www.meneame.net&date=2019-03-25 pobres en comparación con el resto de servicios mencionados anteriormente: Wayback Machine, Archive.is, meneame/20190326020342
o Perma.cc. Y servicios que he posicionado en mi clasificación personal como de menor importancia como Freezepage, Archive.st (con su 2019" class="content-link" style="color: rgb(227, 86, 20)" data-toggle="popover" data-popover-type="link" data-popover-url="/tooltip/link/2019">png completo) archivan la página más fielmente. Sólo fracasan en este caso Megalodon.jp y los servicios de caché (excepto sogou, que ignora la etiqueta meta no cache, aunque http://snapshot.sogoucdn.com/websnapshot?ie=utf8&url=http://www.meneame.net/&did=cd73728bc85adbca-6a7b5e4a9d9fbe2a-bcabb760432374ee937d35a2351a1341&k=254d189455e169b61777cbc13063c009&encodedquery=meneame&query=meneame&&p=40040100&dp=1&w=01020400&m=0&st=1, excepto usándose como http:
Viví durante dos años y medio en una furgoneta "camperizada" en Londres (respondo tus dudas por si te animas)
Durante dos años y medio viví en una furgoneta camperizada en Londres llevando una vida totalmente normal (trabajo, amigos, etc...)
Mi furgoneta era una Ford Transit que adquirí a un colega de trabajo inglés que estuvo viviendo en ella durante 4 años en Londres. Era una "camperización" no al uso ya que su finalidad era la de ser indetectable desde el exterior.
Esto me permitió aparcar (y vivir) en zonas bien situadas (lógicamente fuera de la zona de "congestión" de Londres).
La furgoneta estaba equipada con:
- Cama fija con espacio de almacenamiento debajo
- WC portátil (del lidl) para uso muy ocasional
- Grifo/Hornillo de gas (el típico de las auto caravanas)
- Mesa plegable para portátil/tablet/etc..
- Batería auxiliar
Y ya hablando de la camperización:
- Techo solar / vengilación
- No había ninguna ventana exterior excepto el techo solar (y las del espacio de conductor)
- Separación con cabina mediante panel con ventana
- Por fuera la furgoneta tenia pegatinas de una "charity"